本站所有内容均由自动化程序抓取自第三方网站,部分内容未及时审核,如有侵权,违规,请联系我们第一时间删除!QQ:3963907323
Clash 小火箭 v2ray节点购买
好用的梯子,海外网络,快速稳定
GoogleOCRFlux 背景解析
OCRFlux 是一款基于多模态大语言模型的轻量型工具,专注于将 PDF 与图像文本高质量转换为结构化 Markdown 格式。在保留原始结构的同时,能够自动处理多栏排版、复杂布局、识别复杂表格、数学公式等元素,自动清除页眉页脚,以及跨页内容合并等功能。

转换能力如何提升效率
该工具在发行的 OCRFlux‑bench‑single 基准测试中,Edit Distance Similarity(EDS)取得显著提升:相比 olmOCR-7B-0225-preview 提高约 0.095,相对 Nanonets‑OCR‑s 提高约 0.109,相对于 MonkeyOCR 则提高近 0.187。这些提升主要得益于其在复杂表格解析与跨行跨列单元格处理上表现更优。
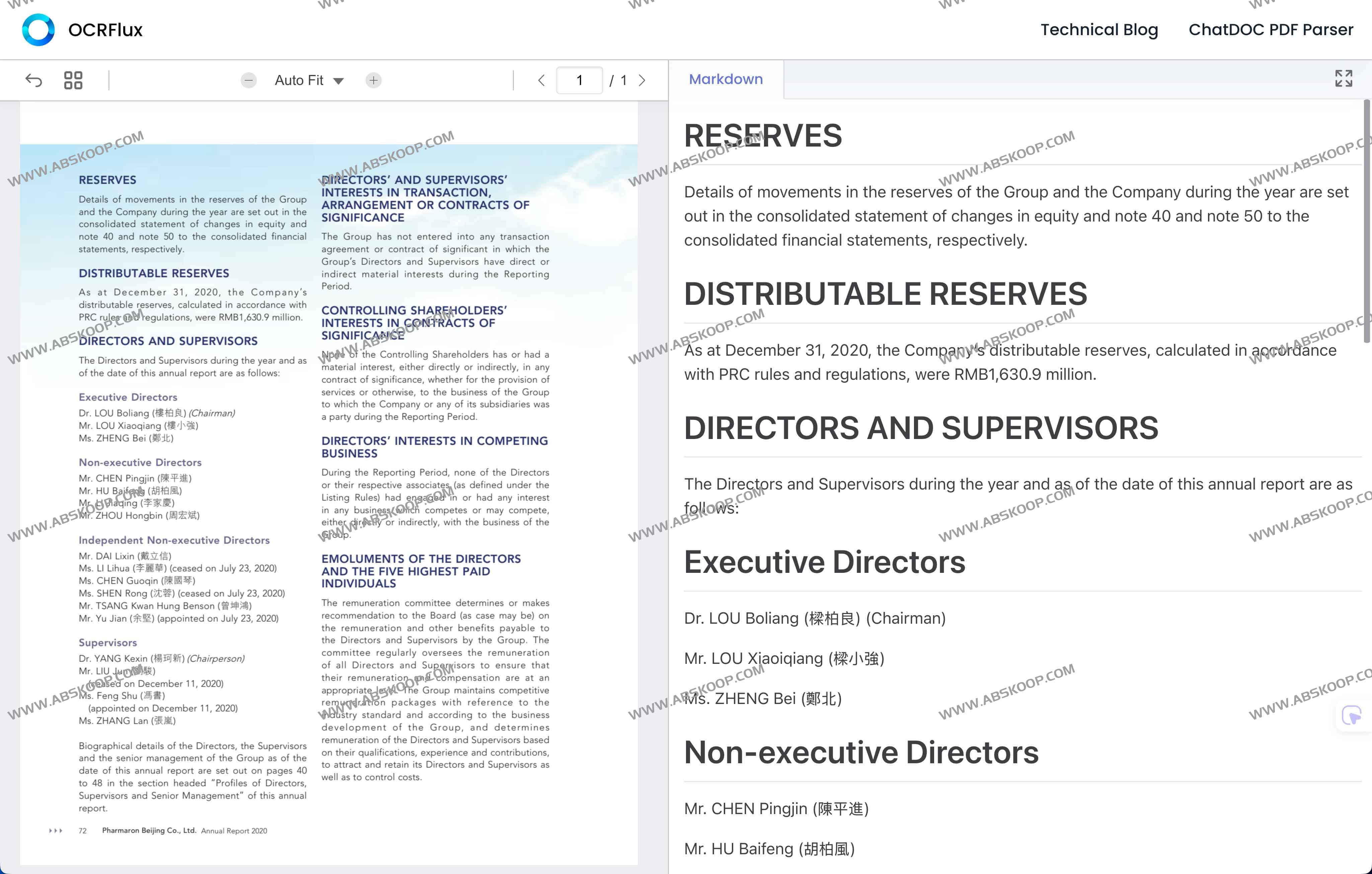
跨页合并识别率达 98.3%
OCRFlux 是首个支持原生跨页表格/段落合并的开源文档解析工具,能够自动检测并整合跨多页的内容,确保文档结构连贯一致。实际测试准确率高达 98.3%。
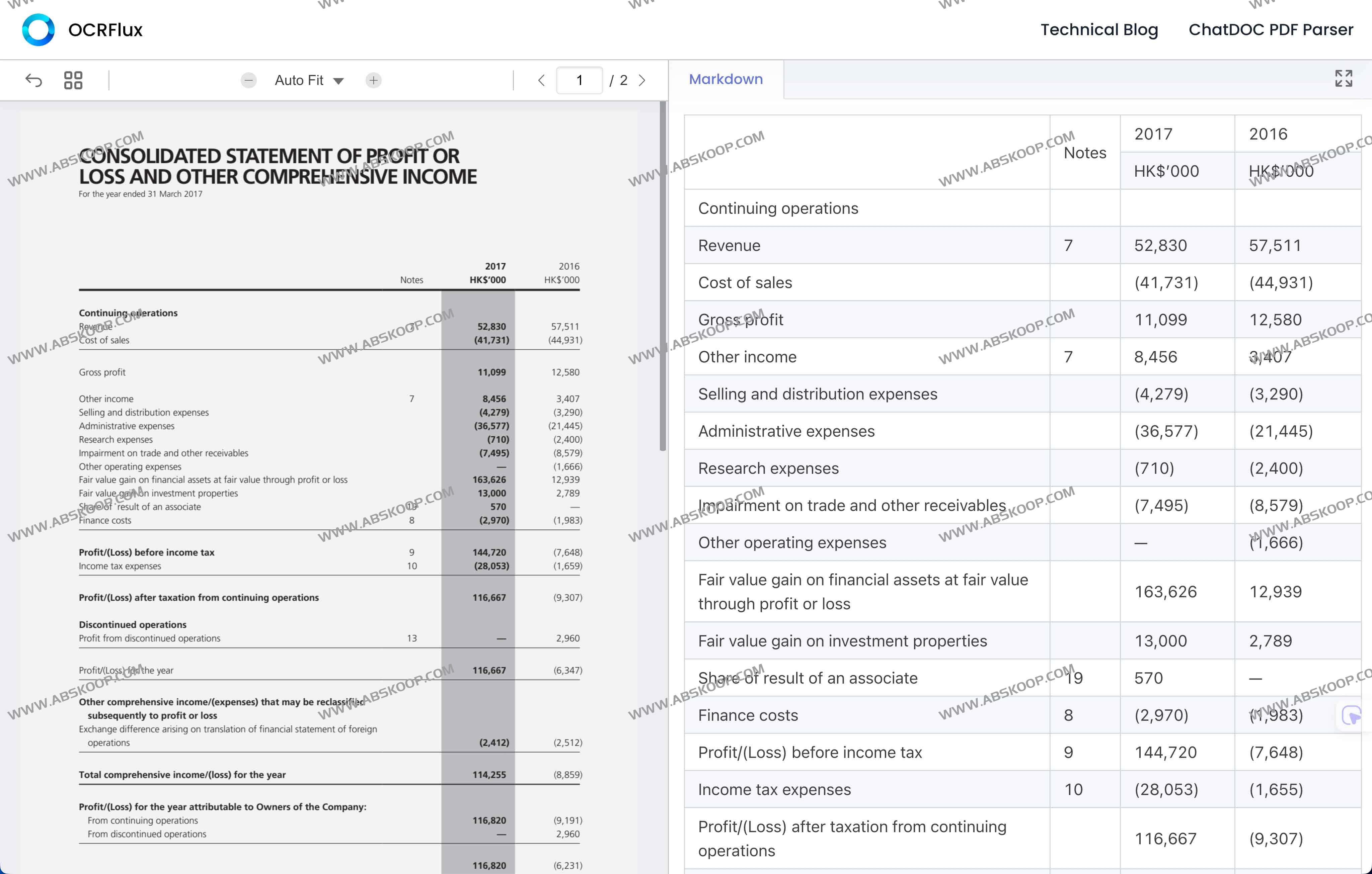
高效性能与轻量参数
工具所采用的模型参数仅为 30 亿(3B),在 GTX 3090 GPU 上处理效率比使用 70 亿(7B)模型的基线方案快约三倍。兼具速度与轻量化,方便部署与集成。
OCRFlux核心功能概览
- 全文解析,自动识别自然阅读顺序文本,适配多栏排版、图文混排等复杂场景
- 支持复杂表格和数学公式识别
- 自动剔除页眉页脚冗余信息
- 跨页表格与段落自动合并,确保输出格式连续整洁
OCRFlux使用体验
用户可通过在线演示体验 OCRFlux 在 PDF 解析上的表现,也可访问 GitHub 仓库查看源码、集成使用或贡献开发。
OCRFlux 提升了 PDF 转 Markdown 的准确性与效率,尤其适用于科研论文、复杂报表与技术文档等内容密集场景。
OCRFlux如何使用
体验地址:https://ocrflux.pdfparser.io/
GitHub地址:https://github.com/chatdoc-com/OCRFlux
本文链接: