本站所有内容均由自动化程序抓取自第三方网站,部分内容未及时审核,如有侵权,违规,请联系我们第一时间删除!QQ:3963907323
Clash 小火箭 v2ray节点购买
好用的梯子,海外网络,快速稳定
Google
文章目录 显示
🚀 Python分布式爬虫与逆向进阶实战课程简介
《Python分布式爬虫与逆向工程进阶实战课》覆盖从入门到企业级应用的完整链路。课程从HTTP请求基础出发,逐步深入数据解析、持久化存储、分布式架构、模拟登录、验证码识别、反爬突破与逆向工程,为需要系统学习数据采集技术的开发者打造一套结构清晰、实践充足的训练方案。
内容横跨 Requests、Scrapy、Scrapy-Redis、MongoDB、Redis、Selenium、OpenCV、OCR 等核心技术栈,通过大量真实网站案例让学习者掌握稳定抓取与反爬规避能力。
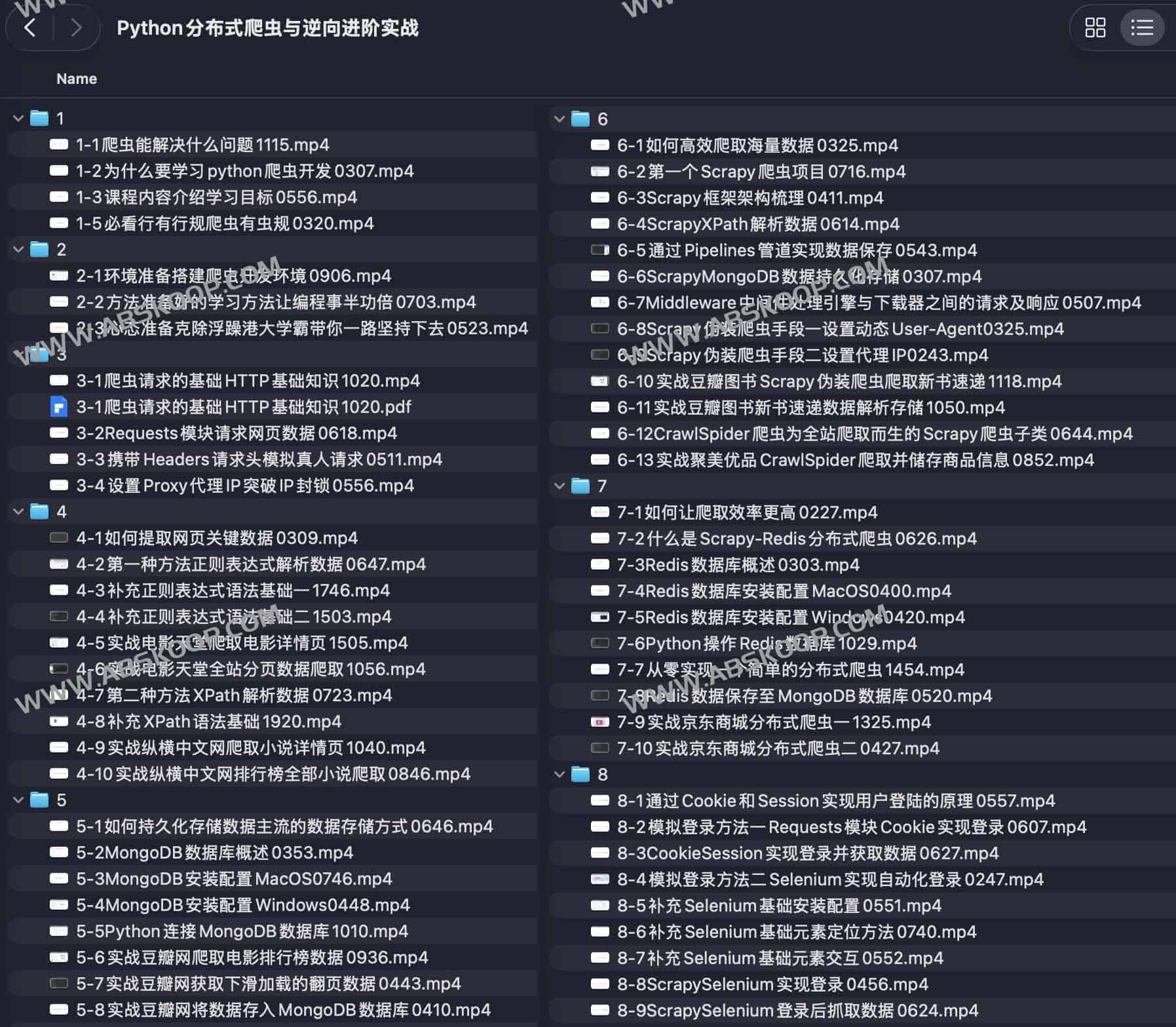
🧩 课程模块结构
1|爬虫能做什么
解析数据采集的应用场景、行业价值、学习目标与必备规范,帮助建立系统化认知。
2|学习准备:环境、方法与心态
搭建爬虫开发环境,了解高效学习方法,并从真实经验中找到持续进步的路径。
3|HTTP请求与网页数据获取
掌握网络通信基础与浏览器行为模拟:
- HTTP 请求、响应结构
- Requests 获取网页数据
- Headers 模拟真实用户行为
- Proxy 代理突破IP限制
4|网页数据解析技术
从数据中提取有效信息:
- 正则表达式解析
- XPath 结构化解析
- 大量案例:电影网站、小说站点、分页抓取
5|数据存储与持久化
掌握主流数据库与实践流程:
- MongoDB 基础与安装
- Python 连接数据库
- 豆瓣榜单抓取并存储
6|Scrapy框架系统实战
构建高性能爬虫框架:
- Scrapy 架构核心逻辑
- XPath 解析与 Pipelines 存储
- Middleware 中间件
- 代理、UA池等高级伪装
- CrawlSpider 全站抓取
- 豆瓣图书、聚美优品项目演练
7|Scrapy-Redis 分布式爬虫
打造可扩展的高并发数据采集系统:
- Redis 数据结构
- 分布式调度
- 数据入库流程
- 京东商城分布式案例
8|模拟登录与自动化抓取
掌握多种登录技术:
- Cookie / Session 登录原理
- Requests 模拟登录
- Selenium 自动化登录
- Scrapy + Selenium 登录并抓取
9|OpenCV 图像识别基础
为验证码识别和反爬突破打基础:
- 像素处理
- 色彩修改
- ROI 区域选择
- 二值化、平滑、形态学操作
- 滑块验证码模板匹配
10|OCR 与验证码识别链路
在真实业务中识别验证码:
- 百度OCR 云服务
- OpenCV 验证码处理
- Selenium 行为模拟
- 滑块轨迹算法与误差处理
11|模型训练与AI识别验证码
借助机器学习提升识别效果:
- EasyDL 初识
- 批量采集验证码
- 标注训练模型
- API 调用识别
12|反爬策略与逆向工程进阶
应对复杂站点:
- 常见反爬逻辑
- 加密方式解析(Base、Unicode、Hex 等)
- Python 实现加解密
- CSS 偏移破解
- ZiRoom 逆向与数据获取实战
🎯 课程适合人群
- 希望从零掌握爬虫技术的学习者
- 想进一步提升数据采集能力的后端工程师
- 对分布式、数据工程方向感兴趣的开发者
- 在真实项目中遇到反爬、登录、验证码等难题的技术人员
📌 课程收益
你将具备从入门到进阶的完整采集能力:
- 构建稳定、可扩展的爬虫系统
- 破解常见反爬策略
- 使用分布式架构提升性能
- 熟练处理验证码、模拟登录与逆向逻辑
- 实现企业级数据采集的全部流程
适用于个人项目、数据工程场景与企业级应用。
🧩Python分布式爬虫与逆向进阶实战学习地址
学习地址:夸克
我用夸克网盘给你分享了「Python分布式爬虫与逆向进阶实战」,点击链接或复制整段内容,打开「夸克APP」即可获取。
/~555739PB7L~:/
链接:https://pan.quark.cn/s/9e7bfc8fb387